
この記事では、「任意の文字を含まない」や「任意の文字列(パターン)を含まない」など、否定の意味を持った正規表現について、解説します。
特に、後述する「否定先読み・戻り読み」を利用した表現は、その仕様が初学者にはやや混乱しやすいため、整理しながら補足としてまとめました。
否定の正規表現について

なるほど、良い質問じゃな!ところで、おぬしの考えている条件は、1文字か?それとも、2文字以上の文字列のパターンか・・?

え〜っと・・・。
「〜を含まない」といった、否定の意味を持つ正規表現を記述する場合、下記のように、大きく分けて2種類のケースがあります。
「特定の1文字を含まない」といった否定表現か、もしくは「正規表現パターンを含まない」といった表現かで、大きく解決の方針が異なる点に注意して下さい。
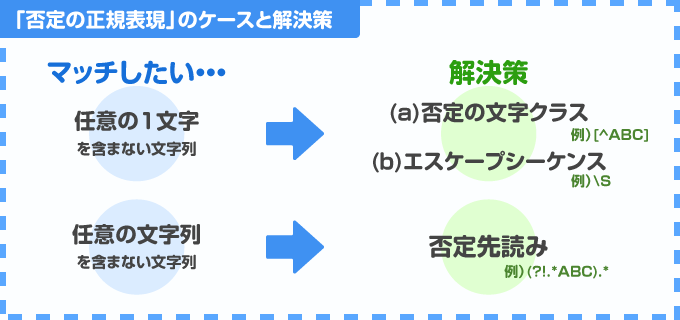
特定の1文字だけを否定したい場合は非常にシンプルです。この場合、「文字クラス」、もしくはエスケープシーケンスで表される文字型を利用する事で表現できます。
一方で、特定の正規表現パターンを否定したい場合、少し記述が複雑になります。今回は「否定先読み」を利用した表現を、この記事の後半にご紹介します。
できるだけ簡単にに済ませたかったけど、なんだか奥が深そうだね・・。
大丈夫じゃよ。落ち着いて読んでいけば、どちらもそれほど難しいものではないのじゃ。
基本的な正規表現の記法はこの記事では触れませんので、不安な方はこちらの記事も合わせてご参照下さい:
それでは、順番に詳しく見ていきます。
任意の一文字を含まない文字列の正規表現
a「否定の文字クラス」を利用した表現
まず前提知識として、正規表現には「指定した文字のうち、いずれかの文字」といったパターンを表現できる、「文字クラス」という記法がありました。
さて、このような文字クラスは、例えば、[^abcdeb ] のように、「^(キャレット)」を開始カッコの直後に付加することで「否定の文字クラス(Negative Character Class)」の表現を行うことができます。キャレットがある事で、「カッコ内に指定した文字以外の文字」という「除外」の意味をもった表現に変わるのです。
// 否定の文字クラス: AかBかCのいずれか以外の一文字
[^ABC]ご参考まで、下記により具体的な使用例をいくつかあげます。
例) アルファベットを含まない文字列
文字クラスでは、「-(ハイフン)」を利用して、「[a-z]」と記述すれば、文字コード上の範囲「a から z まで」を指定することができるのでした。これをそのまま否定文字クラスの表現にする事ができます。量指定子の「+(1文字以上の連続)」を組み合わせると「アルファベット以外の文字で構成された文字列」をマッチすることができます。
// アルファベット(小文字、大文字)以外の文字の連続
[^a-zA-Z]+例) スペースを含まない文字列
正規表現において、空白(スペース)は、エスケープせず、そのまま記載できるのでした。また、下記の例で使用する両指定子「+」は、「直前のパターンの1回以上の連続」を表します。
// 半角スペースを含まない1文字以上の連続
[^ ]+
// 全角スペースを含まない1文字以上の連続
[^ ]+
// 全角か半角かのスペースを含まない1文字以上の連続
[^ ]+例)数字を含まないの文字列
文字クラスを利用した、数字以外で構成された文字列の正規表現です。
// アルファベット(小文字、大文字)以外の文字の連続
[^0-9]+例)特定の記号以外の文字列
特殊な記号を全てマッチして取り除きたい時、除外したい記号を全て文字クラスに含める必要があります。エスケープが必要な特殊文字に注意して下さい。
// 記号以外の文字列
[^!"#$%&'()\*\+\-\.,\/:;<=>?@\[\\\]^_`{|}~]+例)特定の文字以外は許可しない
例えば「特定の文字列以外の入力を禁止したいフォーム」などでは、否定の文字クラスを使わずに、むしろ許可したい文字のみを文字クラスに含めて、限定度を高めたほうが、目的に合致する場合があります。入力を認めたい文字や記号があれば、任意で文字クラス内に追加してあげて下さい。
// 特定の文字のみを含む文字列
[ぁ-んァ-ン0-9a-zA-Z0-9\-]+b否定の意味をもつ「エスケープシーケンス」の利用
バックスラッシュを使った「エスケープシーケンス」と呼ばれる正規表現の中には「〜以外の一文字」といった、否定的な意味を表すものがあります。これらは上記の文字クラスで行うような表現(それ以外の文字も)簡素に記述することができます。
例)空白文字を含まない文字列
エスケープシーケンス「\s」は、「空白文字(半角スペース、全角スペース、タブ、改行、改ページ)」を表すことができます。
これの反対となるメタ文字「\S」で「空白文字以外の一文字」を表現できます。下記は、空白スペースだけでなく、より上記のような複数の種類の空白文字を含まない表現が記述できます。
// 空白文字を含まない文字の連続
\S+例)数字を含まない文字列
上記の空白文字とよく似ていますが、エスケープシーケンス「\d」は「半角数字いずれか一文字」を表すことができる一方で、「\D」は「半角数字以外の一文字」を表す正規表現です。
// 半角数字を含まない文字の連続
\D+「〜以外の一文字」を表現するエスケープシーケンスの例
さて、「空白文字以外」の例でしたが、他にもいくつかの「〜以外の一文字」を表すエスケープシーケンスが存在します。目的に応じてうまく利用することで、正規表現をシンプルに記述できるでしょう。
| 表現 | 意味 |
|---|---|
| \s | 空白文字(半角スペース、\t、\n、\r、\f)すべての文字。( |\t|\n|\r|\f)と同義 |
| \S | 空白文字以外のすべての文字 |
| \d | 数字。[0-9]と同義 |
| \D | 数字以外の文字列。[^0-9]と同義 |
| \w | すべてのアルファベットとアンダースコアのうち任意の一文字。[a-zA-Z0-9_]と同義 |
| \W | すべてのアルファベットとアンダースコア以外の1文字[^a-zA-Z0-9_]と同義 |
| \l | すべての半角英小文字のうち1文字 |
| \L | すべての半角英小文字の以外の文字1文字(英大文字、数字、全角文字など含む) |
| \u | すべての半角英大文字のうち1文字 |
| \U | すべての半角英大文字以外の1文字(英小文字、数字、全角文字など含む) |
これ以外のエスケープシーケンスに関しては、こちらの記事もご覧ください:
任意の文字列を含まない文字列の正規表現
上記の文字クラスで表現できたのは「指定文字以外の文字」といった記述で、あくまで一文字単位でしか否定を表現することができませんでした。一方で、実際に正規表現を用いて記述したパターンそのものを否定したマッチング表現(=パターンの否定表現)も存在します。「パターンの否定」を利用する正規表現に「否定先読み」「否定戻り読み」があります。
今回、「否定先読み」を利用した記述方法をご紹介します。
否定先読みとは、正規表現のマッチング処理位置から前方(左に向かって処理がすすみます)に対して、『「(?!」「)」でくくったサブパターンがマッチしないこと』を吟味(テスト)するための記述法です。

否定先読み・戻り読みの補足解説(ページ内リンク)をこの記事の末尾に追加しましたので、ご一読下さい。
a特定のパターンで開始しない文字列
下記は、否定先読みを用いて、『「^」すなわち文頭の直後に、指定のサブパターンを含まない文字列』をマッチングする表現です。
// PATTERN で開始しない文字列の表現
^(?!PATTERN).*$上記の例で、「.*」で改行以外の文字列の0回以上の連続を表していますが、この条件は必要に応じて任意に変更してください。
また、今回処理対象のテキスト範囲を明示するため、すべて「^(行の先頭)」「$(行の末尾)」で囲みます。行頭と行末の定義は、正規表現エンジンの仕様や、マルチラインモードとシングルラインモードで大きく意味が変わりますので、利用しているプログラミング言語の振る舞いに注意して下さい。
b特定のパターンで終了しない文字列
こちらは、否定戻り読みを用いて、「$」が示す「文末」の直前に特定のパターンを含まない文字列をマッチングします。同じく、「.*」は任意に変更できます。
// PATTERNで終了しない文字列の表現
^.*(?<!PATTERN)$c特定のパターンを含まない文字列
こちは、否定先読みを応用したものです。パターンの出現位置を限定せず、文内に「特定の文字列を含まない」パターンを記述する方法です。
// PATTERNを含まない文字列
^(?!.*PATTERN).*$[a]と比べて、カッコ内のサブパターンの最初に量指定子「.*」を追加しました。これで行内での位置を問わずにPATTERNのマッチング成否に関して、吟味を行うことができます。
【補足】 否定先読み、否定戻り読みについて
否定先読み・戻り読みは、理解するまでやや混乱しやすいですので、補足解説を加えておきます。
否定先読み(Negative lookahead)は、「(?!」と、「)」で囲んだ中に、特定の正規表現(サブパターンと呼びます)を書き込むことで記述できます。
「否定先読み」の記述法

一方で、否定戻り読み(Negative lookbehind)は、「(?<!」「)」でサブパターンを囲みます。「否定後読み」と呼ばれることもあります。
「否定戻り読み」の記述法

「否定先読み・戻り読み」で注意が必要なのは、このカッコ内に記述されるパターン(=サブパターン)は、メインのマッチング検索の処理とは異なり、その処理の後に「消費(Consume)される」ことはなく、一時的な吟味(テスト)の目的にのみ利用されるという点です。
「消費されない」が意味するところにご注意下さい。これはすなわち、
- サブパターンがマッチしてもは、メイン処理のように後方参照することができない。
- サブパターンマッチングの成否に関する吟味が終わった後、処理位置が元の場所に帰ってきて、そこから再開される。
という事です。
「否定先読み」では、メインの走査の位置よりも「前方」を吟味して、カッコ内の別のパターンへのマッチングを吟味します。これが「先読み」という名前の由縁となります。このようなメインの走査処理から独立した吟味(テスト)は「Assertion(言明)」と呼ばれます。一方で「否定戻り読み」では、メインの処理より「後方を」テストする事は、その名前からも想像できると思います。
・・・のような説明だけでは、非常にわかりにくいですので、具体例を見てみます。
否定先読み/戻り読みの具体的な使用例
それでは、下記の例文(1行)を対象に、上記の否定先読み・戻り読みパターンを適応してみます。どこかで聞き覚えのある例文かもしれません。
この例文に対して、いくつかの否定の言明を検証して見ます。
「おれは」で開始しない文字列
「『おれは』で開始しない1行」という正規表現を考えてみます。否定先読みを使った表現は下記のようになるはずです。
// 「おれは」で開始しない文字列
^(?!おれは).*$「^」が行頭、「.(ドット)」は改行以外のあらゆる一文字、「.(ドット)」は、0回か1回以上の連続を表す量指定子です。つまり、上記は「直後に『おれは』が現れない行頭と、その直後から続く改行以外の文字の0回以上の連続」をマッチする正規表現です。
例文は、行頭に「おれは」が出現していますので、この上記の正規表現はマッチを見つけられません。「おれは」がサブパターンにマッチした時点で、この正規表現全体のマッチは不成立です。

「私は」で開始しない文字列
さらに理解を深めるため、否定先読みのサブパターンを少しだけ変更し、同じ例文を適応してみます。「おれは」でなく、代わりに「私は」としてみます。
// 「私は」で開始しない文字列
^(?!私は).*$例文は、明らかに行頭に「私は」が現れませんので、この正規表現全体は例文にマッチすることになります。サブパターン「私は」の否定のテストをパスした後、その後の処理が、直前のマッチの直後(=行頭の直後)から開始することに注意して下さい。つまり、マッチは「おれは海賊王になる男だ!」です。
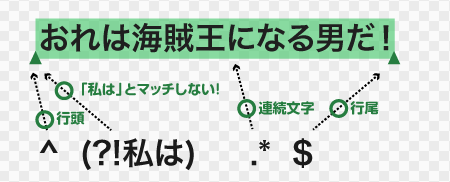
「海賊王」を含まない文字列
さて、本記事の主題である「〜を含まない文字列」です。
否定先読みのカッコ内のサブパターンを「.*海賊王」としてみます。これにより、サブパターンが「海賊王」もしくは「・・・海賊王」を表すようになります。
// 「海賊王」を含まない文字列
^(?!.*海賊王).*$上記は読み解くと、「直後に『海賊王』か、もしくは『・・・海賊王』が現れない行頭と、その直後に続く改行以外の文字の0回以上の連続」です。これにより、行内のいずれかの位置に「海賊王」が含まれていればマッチしない正規表現、すなわち「海賊王を含まない文字列」といった、否定の正規表現が完成します。

「.*」の働きにより、「海賊王」が行頭に現れても、行尾にあらわれても、どちらでも見つける事ができるのは、理解できると思います。
「海軍」を含まない文字列
確認のため、さらにサブパターンを変更してみます。「海軍」であればどうでしょうか?
// 「海軍」を含まない文字列
^(?!.*海軍).*$
文字列中のどの位置にも「海軍」は現れませんので、全体の正規表現はマッチすることになります。これで「〜を含まない文字列」の正規表現が正しく動作している事が確かめられました。
参考:肯定先読みの利用例
ちなみに「(?=」 と「)」で囲まれる言明は「肯定先読み」と呼ばれます。

肯定先読みを使えば、逆に『「海賊王」を含む文字列』をマッチできます。ご参考まで。

以上、否定先読みの「表現がマッチしない(はじめての)位置を探す」という振る舞いを利用した表現の例でした。言明のバリエーションは下記の4つのセットが代表的です。
| 名前 | 表現 | 詳細 |
| 否定先読み (Negative lookahead) | (?!pattern) | 開始位置から前を読んで、pattern がマッチしなければテストはパス |
| 否定後読み (Negative lookbehind) | (?<!pattern) | 開始位置から後ろを読んで、pattern がマッチしなければテストはパス |
| 肯定先読み (Positive lookahead) | (?=pattern) | 開始位置から前を読んで、pattern がマッチすればテストはパス |
| 肯定後読み (Positive lookbehind) | (?<=pattern) | 開始位置から後ろを読んで、pattern がマッチすればテストはパス |
上記の中でも、特に否定先読み・戻り読みは、利用すると非常に多様な正規表現が可能になります。ぜひマスターしてみて下さい。今回紹介した、否定先読み、否定戻り読みに関しては、こちらにも詳しくまとめています。
さて、説明がながくなってしまったが、うまく理解できたかな?

なんとなくはね!とりあえずトライしてみるよ〜。
そうじゃな、まずは自分でやってみることじゃ。きっと忘れた頃にまた必要になるので、その時はまたこのページに帰ってくればいいのじゃ。
【補足】.htaccess では、 否定のパターンに「!」が使える
もしあなたが、正規表現を .htaccess でリダイレクト処理のために記述しているならば、朗報です。mod_rewrite エンジンで、RewruteCond や RewriteRule を記載する際には、正規表現パターンの否定を表すことが出来てしまいます。
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{REQUEST_URI} !^/about
RewriteRule (.*) http://example.com/$1 [R=301,L]
</IfModule>.htaccess による、リダイレクト設定にかんしてです:
アパッチのドキュメントにも言及があります。
参考情報
また、今回1行を対象にするように「^」「$」のアンカーを利用しました。一般的な正規表現については、こちらを御覧ください。
こちらは、文書全体を処理する時の表現です。
基本的な正規表現については、こちらにまとまっています。


「〜にマッチしない」の正規表現が書きたいよ〜