正規表現で、便利だが、分かりにくい「否定先読み」「肯定先読み」についてまとめました。
正規表現「否定先読み」とは?
正規表現における「否定先読み(Negative lookahead)」とは、メインのマッチング処理とは独立したサブパターンのマッチングの吟味(テスト)の事です。「(?!」と「)」で、サブパターンを囲み、このような記述を用います。

ここでいう「吟味(テスト)」とは、通常の「(」「)」で囲むようなサブパターンのマッチングと異なり、もしそのサブパターンのマッチが見かっても、マッチした文字列は「消費(Consume)」されず、同時に格納(Capture)されません。
これはすなわち、下記を意味します。
- その後に実行されるマッチング処理の位置に影響しない。
- サブパターンにマッチした文字列を後方参照するできない。
「処理位置の前方を吟味して、元の位置に戻ってきて処理を再開する。」これが先読みという由縁です。このようなテストを「言明(Assertion)」と言います。このような言明の表現は、否定/肯定の先読み/後読みとして、4つのパターンがあることでよく知られています。
| 名前 | 表現 | 詳細 |
| 否定先読み (Negative lookahead) | (?!pattern) | 開始位置から前を読んで、pattern がマッチしなければテストはパス |
| 否定後読み (Negative lookbehind) | (?<!pattern) | 開始位置から後ろを読んで、pattern がマッチしなければテストはパス |
| 肯定先読み (Positive lookahead) | (?=pattern) | 開始位置から前を読んで、pattern がマッチすればテストはパス |
| 肯定後読み (Positive lookbehind) | (?<=pattern) | 開始位置から後ろを読んで、pattern がマッチすればテストはパス |
否定先読みの使用例
説明だけではだいたいよくわからないので、まずは、否定先読み表現の例を見てみましょう。対象の文字列はこちらを吟味します。
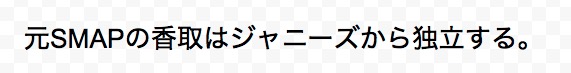
例1-1「元SMAP」で開始しない1行
基本的な「行頭」を表す位置指定子「^」の直後に、先読みの「元SMAP」が開始するかどうかを吟味します。
// 元スマップで開始しない1行 ^(?!元スマップ).*$
「.(ドット)」は改行以外の1文字、「*」は、直前のパターンの0回以上の繰り返しを表す量指定子、「$」は行末です。上記の対象文字列は、明らかに「元スマップ」で開始していますので、マッチはしません。

比較のため「肯定先読み」で考えています。
※2018/3/1 修正箇所のご連絡ありがとうございました。
例2-1「香取」を含まない1行
さて、前述の例は「行頭」という条件で吟味していましたが、1文全体を対象にしています。
否定先読みを使って、「香取」を含まない1行をマッチングしようとしてみます。
// 香取を含まない1行 ^(?!.*香取).*$

正規表現「肯定先読み」とは?
先に否定先読みを紹介しましたが、肯定先読み(Positive lookahead)はもうすこしシンプルです。
「(?=」と「」)でパターンを囲みます。

肯定先読みの例
例1「元SMAP」で開始する1行
肯定の先読みは、その名の通り、カッコ内のサブパターンがマッチすればテストが成功します。ただし、この下記のようなシンプルなケースでは合肯定先読みを利用する必要はありません。
// 元スマップで開始する1行 ^(?=元スマップ).*$
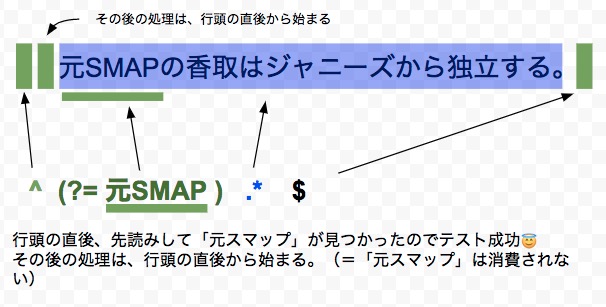
ただし、このようなシンプルなケースでは合肯定先読みを利用する必要はありません。この例は、下記のシンプルな正規表現と(処理内容の違いはありますが)ほぼ同じ結果を得られます。
// 元スマップで開始する1行 ^元スマップ.*$
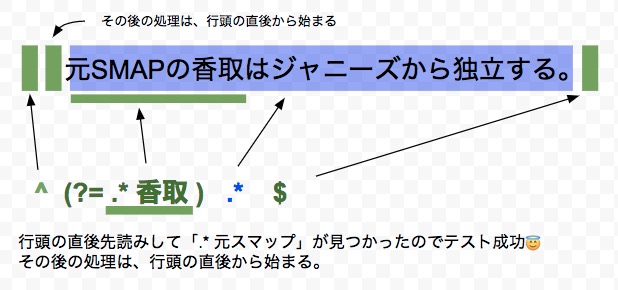
例1-2香取を含む1行(部分一致)
サブパターンのテストが成功しても、マッチ文字列は「消費されない」性質を利用して、部分一致による文章全体をマッチングします。
もう想像が付きそうですが、香取を含むには、肯定先読みで表現できます。
// 香取を含む1行 ^(?=.*香取).*$
以上です。
正規表現に関する参考情報
正規表現について、基礎的な内容、メタ文字の一覧やサンプルを広くまとめています。

