多くの入門者にとって、「正規表現」は、意味のわからない記号の羅列のように感じられ、とっつきにくさのある記法の一つです。一方で、ひとたび身につければ、非常にパワフルで、幅広く利用でき、ソフトウェア開発、Web開発に大いに役立つことは間違いありません。
今回の記事では、正規表現の概要、基本構文を入門者向けに分かりやすくまとめました。また、末尾にいくつかのサンプルをつけてまとめましたので、ご覧ください。
正規表現とは?
正規表現とは
正規表現(せいきひょうげん)とは、文字列の中に見つかる「パターン」を表現する記述方法です。この「パターン」を記述することによって、パターンにマッチする複数の文字列(=文字列の集合)を、シンプルに表現することができます。
「パターン」って何・・?
急に「パターン」と言われても、入門者にとっては、なんだか曖昧すぎて、具体的なイメージが湧きにくいかもしれません。正規表現における「パターン」とは「文字列のなかで、文字の発生のしかたに関する条件(ルール)」のようなものです。
やっぱりまだ、わかりにくいと思いますので、具体例と一緒に見てみましょう。
下記に、いくつかの条件(ルール)の例と、そのルールに当てはまる文字列の例、ついでに、当てはまらない例も列挙しています。
| 文字列のルール | 当てはまる例 | 当てはまらない例 |
|---|---|---|
| 「東京」で始まる文字列 | 東京都 東京タワー 東京好き | 埼玉県 今日も東京は晴れ。 |
| 「ね。」で終わる文字列 | いいね。 ねねね。 だよね。 | いいわ。 いいのね! |
| 「〇〇cm」 | 30cm 1,000,000cm 50cm | 33m 150メートル |
それぞれルールを満たす文字列は、上記の例の他にも無数にあり、(多すぎて)すべてを書ききる事は難しいでしょう。そのような場合に、「文字のならびの条件」自体をシンプルに記述するための方法こそ、「正規表現」なのです。そして、このような条件の事を「パターン」と呼びます。
正規表現の基本構文
正規表現によるパターンは、「通常の文字(※リテラルとよんで区別します)」と「メタ文字」と呼ばれる、特殊な役割を与えられた記号を組み合わせて記述します。
例えば、上記であげた例はそれぞれ、正規表現を使って、それぞれこのように表せます。
// 「東京」で始まる文字列
^東京.*
// 「だよね。」で終わる文字列
.*だよね。$
// 「〇〇cm」と書かれた数値
[0-9]+cm「.」「[」「^」「$」などの記号のようなものが、まさに「メタ文字」と呼ばれる文字なのですが、見たことのない人に取っては、奇妙な記号の羅列のように見えてしまうでしょう。それぞれのメタ文字について、詳しくは後のセクションで解説していきます。
※「リテラル(literal)とは、英語で「文字通りの」という意味の形容詞です。「(The) literals」というと「文字通りの意味を持った文字群」というような表現となり、「特殊な意味をもったメタ文字に対して、文字通りの意味をもったリテラル」と対比的に使われる呼称となっています。
具体的な利用ケース
繰り返しになりますが、パターンとは、文字列を特徴づけるルールや条件であり、正規表現は、通常のテキスト文字とメタ文字(特殊文字)を組み合わせてパターンを記述するための記法と言えます。
特定のパターンを持つ無数の文字列をすべて一通りに書き表す事ができるため、しばしば文字列の検索や置換に利用されています。例えば、MacOS 標準のテキストエディタや、Google Document の「検索と置換(Cmd + Shift + H)」機能からも、正規表現が利用できます。
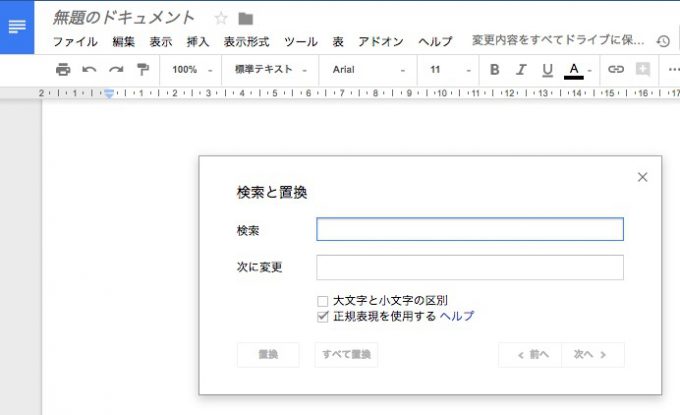
パターンにマッチする文字列を見つけて、特定のルールで置き換えたい
また、例えば、事務作業で下記のような場面に出くわすかもしれません。
「このテキストファイルの中で、全角数字で記載された場所があれば見つけて、半角に直したい」
アプリに付随している通常の検索ボックス機能を使えば、特定の文字列は検索できますが、9文字ある数字すべて、「1→1、2→2、3→3、・・・・」と、順番に検索ボックスに入力して見つけていくのは、ちょっと骨が折れますよね。
そのような場合「全角数字、なんでもいいから全て」というルールを検索ボックスに打ち込めたらいいのに・・、と感じるかもしれません。まさに正規表現は、そのようなルール、すなわち「パターン」を記述するために利用できます。
「すべての全角数字で構成された文字列」は、正規表現では下記のように記述できます。
// すべての全角数字の文字列を表す正規表現
[0-9].+それでは、上記の例のような正規表現のメタ文字の意味を、このあと1つずつ紹介していきます。
正規表現のメタ文字(特殊文字)
正規表現は、「通常の文字(リテラル)」と「メタ文字」によって構成されます。このセクションでは、メタ文字を使った、基本的な正規表現によるパターンの記述法を一つずつ見ていきます。
あらゆる一文字を表す「.(ドット)」
それでは、早速メタ文字を利用していきます。
正規表現での最もよく利用するメタ文字の一つは「.(ドット)」です。これを使えば、改行以外のあらゆる一文字を表す事ができます。これはいわゆる「ワイルドカード」という役目をします。たとえば、「.」であれば、「あ」「ア」「!」などなんでもいい一文字です。例を見てみます。
// 正規表現 ....が大好き。 // マッチする文字列 ラーメンが大好き。 早寝早起が大好き。 焼肉定食が大好き。
「.」を4つ並べば、何の文字かを問わずに「4文字の文字列」を表す、というわけですね。
上記のように、文字数の分だけ、何度も「.(ドット)」を繰り返し入力するのは、ちょっと大変です。マッチしたい文字は4文字かもしれませんし、30文字かもしれません。そんな時、正規表現には、そのパターンが何回繰り返されるかを単純に表現する便利な方法があります。
0回以上の繰り返し「*」
「* (アスタリスク)」は、「その直前の文字が0回以上繰り返す」というパターンを表します。0回以上、というのは、その文字が現れない場合も含める表現です。
具体例を見てみましょう:
// 正規表現の例
チャーシューたっ*くさん
// マッチする文字列
チャーシューたくさん
チャーシューたっくさん
チャーシューたっっっっっっっっくさん「っ」があろうとなかろうと、10回、100回とたくさん連続で出現してもなお、すべてを「*」を使って表現できるというわけです。

「*」は、ターミナルのコマンド入力でも「ワイルドカード」としてよく利用される文字ですので、覚えやすいね
このような、直前の正規表現の「パターンの繰り返し回数」を指定するメタ文字は「量指定子」と呼ばれることもあります。
1回以上の繰り返し「+」
それでは、他の量指定子も見てみましょう。
量指定子「+(プラス)」は、直前のパターンの1回以上の繰り返しを表します。
さきほどの「.」と組み合わせてみます。
// 正規表現の例
.+も好きです。
// マッチする文字列
トンカツにソースをたっぷりかけるのもわりと好きです。
フルーツも好きです。+(プラス)だから「ゼロよりは大きい回数の繰り返し」だと、僕は覚えたよ〜。
0回か、1回の繰り返し「?」
0回か1回だけという量指定子もあります。
// 正規表現の例
いらいっしゃいませ〜?。
// マッチする文字列
いらいっしゃいませ。
いらいっしゃいませ〜。あるの?ないの?どっちなの?!というイメージの「?」だね。あくまで僕の覚え方だよ〜。
繰り返しの回数の指定「{n,m}」
より細かい繰り返し回数の指定方法もあります。「{」「}」の括弧を使って、繰り返し回数の上限、下限を指定できます。これは便利ですね。
// 正規表現の例
替え玉一丁!{1,6}
// マッチする文字列
替え玉一丁!
替え玉一丁!!!
替え玉一丁!!!!!!
上限、下限を省略することもできます。上限値を省略した例です。
// 正規表現の例
お水くださ〜{1,}い。
// マッチする文字列
お水くださ〜い。
お水くださ〜〜い。
お水くださ〜〜〜〜〜〜〜〜〜い。
繰り返しの下限値を省略した例です。
// 正規表現の例
バリカタはできますか?{,3}
// マッチする文字列
バリカタはできますか
バリカタはできますか?
バリカタはできますか???
{n,m} の記法で、「*」も「+」も「?」も、全部カバーできちゃうんだね・・・。
余談ですが、パターンの繰り返しの指定は「最長一致」「最短一致」の概念に注意する必要があります。こちらに詳しく記載しましたので、ご一読下さい。
いずれかのパターン「|」
ちょっとラーメンの話に限定したいので、もうすこし絞り込みたいです。正規表現では、()を使ってグループ化することができます。また、「|(縦棒、パイプ)」で区切って、「◯|△」とすれば、「◯か△かいずれか」と言った意味を表します。
// 正規表現の例
(塩|醤油|味噌|豚骨)が一番です。
// マッチする文字列
豚骨が一番です。
醤油が一番です。指定した文字のうち、いずれか「文字クラス」
半角の角括弧「[」「]」を使って囲んだ文字であれば、なんであればマッチさせることができる表現です。このような表現は、正規表現において「文字クラス」と呼ばれます。
文字クラスの括弧内には、多くの複数の文字が記述されますが、それ全体で「いずれかの一文字」を表すことに注意して下さい。
// 全角・半角数字の連続 [01234567890123456789] // マッチする文字列 1 9 8
文字クラスの中では、文字コード(ASCIIコード)上で、連続するコードであれば、「-(ハイフン)」で開始終了位置を指定することができます。上記の半角・全角数字の表現は下記のように短縮できます。
// 全角・半角数字の連続
味玉は[0-90-9]+円です。
// マッチする文字列
味玉は100円です。
味玉は999999999円です。ASCIIコードについては、こちらをご覧ください。
指定した文字以外の文字「否定文字クラス」
文字クラスの最初の括弧の直後に「^(ハット)」を加えれば、「否定文字クラス」呼ばれるパターンを記述できます。否定文字クラスは、指定した文字以外の一文字を表します。
// 全角・半角数字以外の文字の連続
[^0-90-9]+
//マッチする文字列
ラーメンひとすじ
abc
山頭火「〜以外の」といった否定のパターンの記述は、注意が必要です。こちらもご一読下さい。
1行の文字列の末尾や、先頭を指定できます。このような文字でなく位置を限定するメタ文字を「アンカー」や、「位置指定子」と呼ぶことがあります。
行頭(行の先頭)「^」
行の先頭は「^(ハット)」を使って表します。
// すべての全角数字の正規表現
^僕は.+。
// マッチする文字列
僕はやっぱり、醤油ラーメンにします。
行末(行の末尾)「$」
行の末尾は「$」を使って表します。
// すべての全角数字の正規表現
.+塩ラーメンでした。$
// マッチする文字列
本当に食べたかったのは、塩ラーメンでした。メタ文字の一覧です:
| 表現 | 意味 |
|---|---|
| . | 改行(\n、\r)を除くすべての文字 |
| ^ | 行頭の位置(シングルラインモード:行頭、マルチライン:文章の頭) |
| $ | 行末の位置 |
| A|B | 「|」の左右の文字列のいずれか(A, Bのいずれか) |
| \X | 直後のメタ文字Xをエスケープする |
| [X] | 文字クラス。カッコ内に指定した文字のうち、いずれかの一文字 |
| [X-Y] | 文字クラス内のハイフンは、文字の文字コード上の範囲を指定できる |
| [^X] | 否定の文字クラス。カッコ内で指定した文字以外のいずれかの一文字 |
| (X) | サブパターン。カッコ内のパターンにマッチした文字列を後方参照できる。ネスト可能。 |
| {Num} | 量指定子。直前のパターンが何回連続するかをNumで指定。 ※「量指定子」セクションを参照 |
正規表現のメタ文字はこちらに詳しくまとめています。
こちらは量指定子の一覧です。
| 量指定子(最長一致) | 最短一致 | 意味 |
| * | *? | 直前のパターンの0回以上連続 |
| + | +? | 直前のパターンの1回以上連続 |
| ? | ?? | 直前のパターンの0回か1回の出現 |
| {N} | - | 直前のパターンのN回の連続 |
| {min,} | {min,}? | 直前のパターンのmin回以上の連続 |
| {,max} | {,max}? | 直前のパターンのmax回以下の連続 |
| {min,max} | {min,max}? | 直前のパターンのmin回からmax回の連続 |
正規表現におけるバックスラッシュ
正規表現において、「\(バックスラッシュ)」は特別な働きをしています。2つのバックスラッシュの機能を紹介します。
1メタ文字・デリミタをエスケープする
メタ文字をエスケープ
正規表現のメタ文字は、特別な意味を持ったものとして処理されます。では例えば、「.(ドット)」そのものをマッチしたい時はどうすればよいのでしょうか?
メタ文字をそのままの文字として認識させたい時はスラッシュを使ってエスケープ(=迂回)します。下記のように、メタ文字の直前にスラッシュを配置することで、直後のメタ文字を通常の文字として認識させることができます。
// ドットをエスケープする
https?://example\.com
// マッチする文字列
https://example.com
http://example.comデリミタをエスケープ
多くのプログラミング言語では、正規表現を記述する際に、何らかの半角文字で、その両端を囲むことになっています。この囲み文字を「デリミタ」と呼びます。デリミタと同じ文字は、正規表現中での混同を避けるため、エスケープする必要があります。
下記はPHPの例です。
// エスケープをデリミタで使ったので、正規表現中でエスケープする。
$pattern = '/https?:\/\/example\.com/';
// 処理対象
$subject = 'http://example.com/';
// 実行
if ( preg_match( $pattern, $subject, $matches ) ) {
echo 'Matched: ' . $matches[0];
}上記のようなURLでは、スラッシュをデリミタに使わないほうが良いでしょう。デリミタによく使われる文字は「#」「@」などがあります。
正規表現のエスケープに関して、こちらの記事もどうぞ:
2エスケープシーケンスを使ったパターン表現の利用
正規表現において、バックスラッシュの役割は、メタ文字をエスケープするだけではありません。エスケープで開始する特殊なメタ文字も存在します。これらは「エスケープシーケンス」と呼ばれ、文字クラスで表していたような、特定の文字集合も「\d」と言った、シンプルで短い表記に置き換えることができます。
下記は、正規表現で利用できるエスケープシーケンスの一覧です。
| 表現 | 制御コードの意味 |
|---|---|
| \a | ベル文字 |
| \cX | Ctrl + X(Xは任意の文字) |
| \n | 改行コード(Line Feed) |
| \r | 改行コード(Carriage Return) |
| \f | 改ページ |
| \R | すべての改行コード(「\n|\r|\n\r」と同義) |
| \t | タブ |
| \v | 垂直タブ |
| \s | 空白文字(半角スペース、\t、\n、\r、\f)すべての文字。( |\t|\n|\r|\f)と同義 |
| \S | 空白文字以外のすべての文字 |
| \d | 数字。[0-9]と同義 |
| \D | 数字以外の文字列。[^0-9]と同義 |
| \w | すべてのアルファベットとアンダースコアのうち任意の一文字。[a-zA-Z0-9_]と同義 |
| \W | すべてのアルファベットとアンダースコア以外の1文字[^a-zA-Z0-9_]と同義 |
| \l | すべての半角英小文字のうち1文字 |
| \L | すべての半角英小文字の以外の文字1文字(英大文字、数字、全角文字など含む) |
| \u | すべての半角英大文字のうち1文字 |
| \U | すべての半角英大文字以外の1文字(英小文字、数字、全角文字など含む) |
| \0 | NULL文字(0の後に数字を続けると、8進数を表す数字を表すエスケープシーケンスとなるので注意) |
正規表現の修飾子
正規表現にはしばしば「修飾子」と呼ばれるオプションを付けて実行します。修飾子は、プログラミング言語や正規表現エンジンによって異なる場合が多く、注意が必要ですが、PHP(PCRE)を例に取って、代表的なものをご紹介します。
大文字・小文字を区別しない「i」
「i」オプションを付けると、大文字と小文字を区別しないでマッチングを行います。
/**
* 「www」を大文字・小文字を問わずにマッチする
*/
// 小文字のwww。i オプションを付加
$pattern = '/www/i';
// 大文字のWWWを含む文字列を検証
$subject = 'My name is WWW-Creators.';
if ( preg_match( $pattern, $subject ) ) {
echo '見つかりました。';
}行単位で検索する「m」
通常、PHPの正規表現エンジンPCRE は、デフォルトでは、複数行のテキストであっても、これをひと続きの文字列として(1行の文字列として)処理します。このとき、位置指定子「$」は文字列全体の末尾とマッチします。
/**
* 「m」オプションの振る舞いを確認する
*/
$ptn = '/.*$/';
$ptn_m = '/.*$/m';
// 改行コードを含む文字列
$subject = 'I am
www-creators.';
// デフォルトモード
if ( preg_match( $ptn, $subject, $result ) ) {
echo $result[0]; // "www-creators."
}
echo '<br>';
// mオプションの振る舞いを検証
if ( preg_match( $ptn_m, $subject, $result ) ) {
echo $result[0]; // "I am"
}
改行コードを無視する「s」
「s」はシングルラインの略です。通常PCREでは「.(ドット)」は「改行コード以外の文字」という定義ですが、このオプションを付けると、「.(ドット)」が改行コードを含めるようになります。
/**
* 「s」オプションの振る舞いを確認する
*/
$ptn = '/^.*/';
$ptn_s = '/^.*/s';
// 改行コードを含む文字列
$subject = 'I am
www-creators.';
// デフォルトモード
if ( preg_match( $ptn, $subject, $result ) ) {
echo $result[0]; // "I am"
}
echo '<br>';
// sオプションの振る舞いを確認
if ( preg_match( $ptn_s, $subject, $result ) ) {
echo $result[0]; // "I am www-creators."
}その他のPCREオプションはPHPドキュメントをご覧下さい。
また、各言語利用可能なオプションや指定方法が異なりますので、PHP以外では、各言語の仕様を確認して下さい。
正規表現のサンプル集
ご参考まで、いくつかの正規表現のサンプルをまとめました。
郵便番号の正規表現
数字とハイフンの組み合わせによる正規表現です。
// 正規表現の例
[0-9]{3}-[0-9]{4}
\d{3}-\d{4}電話番号の正規表現
こちらも数字とハイフンを使ったパターンです。
// 正規表現の例
0[589]0-?[0-9]{4}
0[589]0-?\d{4}-?\d{4}
数字の正規表現に関しては、下記の記事も合わせてご一読下さい。
URLの「WWW」の有り無しを両方マッチする正規表現
もしデリミタが「/(スラッシュ)」でない場合、スラッシュのエスケープは不要です。
// exmample.com, www.example.comを両方マッチ
https:\/\/(www\.)?example\.com
「/archives/xxxx」と数字で終わるURLパス
ワードプレスのURL構造の一つです。数字は何桁でもマッチするようにかきました。
// /archives/1234 のようなURLをマッチ
\/archives/[0-9]+改行をマッチする正規表現
改行をマッチするには、改行コードを探します。改行コードは、OS毎に異なります。
// 改行をマッチする正規表現
\r|\n\r\|\n改行のマッチングに関して、詳しくは「正規表現:改行コードの表現方法」をご一読下さい。
半角スペース、全角スペースをマッチする正規表現
半角・全角スペースは、メタ文字ではありませんので、エスケープが不要です。正規表現中でもそのまま(リテラルで)記載することができます。下記は、見にくいというか見えないですが、半角スペースと全角スペースが文字クラスとして表現されています。
// 半角・全角スペースをマッチする文字クラス
[ ]スペースを含む「空白文字」の正規表現に関しては「正規表現:半角スペース、全角スペースの表現方法。」をご覧ください
おすすめの正規表現チェッカー
手早く正規表現チェックを行えるオンラインツールをいくつか厳選してご紹介します。
正規表現チェッカー
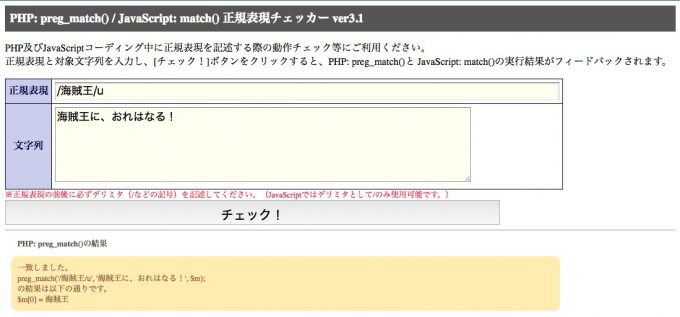
言わずと知れた(?)日本語版のシンプルな正規表現チェッカー。「正規表現 チェック」と検索するとトップに表示されますので、ご存知の方も多いと思います。(2018年3月)
決して多機能ではないですが、日本語かつ、シンプルので、安心感がありますね。入門者におすすめです。
- URL :http://okumocchi.jp/php/re.php
- 対応言語 :PHP, Javascirpt
Debuggex
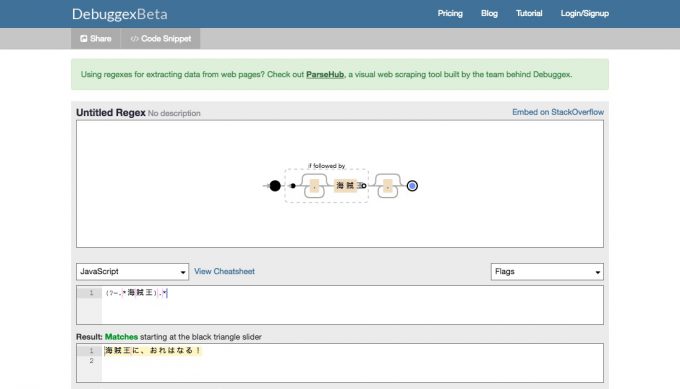
機能が豊富で画面もすっきりして見やすい正規表現チェックツールです。エディターフィールドの関係で、やや日本語が入力しにくいのが難点・・・。
- URL :https://www.debuggex.com/
- 対応言語 :PHP, Javascirpt, Python
- その他の機能:URLによる画面共有、コードスニペットの生成、、リアルタイムチェック、他
Rubular
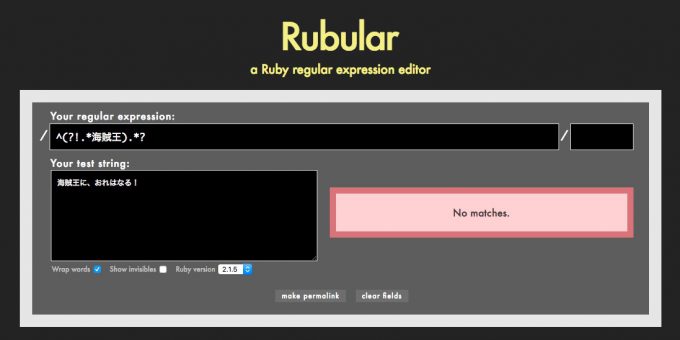
こちらもシンプルなチェックツール。画面がスッキリして見やすいですね。対応言語はRubyのみですが、基本的な正規表現をチェックする限りは問題にならないでしょう。
いちいち実行ボタンを押さなくてもよいのが使いやすいですね。筆者はこちらを最もよく利用します。
- URL :http://www.rubular.com/
- 対応言語 :Ruby
- その他機能 :URLによる画面共有、リアルタイムチェック
まとめ
いかがだったでしょうか?はじめはなんだか得体の知れない者のように感じますが、ひとたび覚えてしまえば、簡単な正規表現はすぐに記述できますし、また非常に便利だと思います。
1点注意が必要なのは、正規表現は「ライブラリ」と呼ばれる処理エンジンがプログラミング言語によって様々だという点です。実際に、プログラミングで利用する場合は、利用している正規表現エンジンの仕様にも気を配る必要がありますので、注意してくださいね。
さて、当サイトでは多くの正規表現のよくある疑問に対する情報をまとめています。気になるものがあればご一読下さい。
正規表現のメタ文字
基本的な表現方法
数字の表現方法
やや高度な正規表現
正規表現の参考情報
以下、参考リンクです:
また、Vim (テキストエディタ)を利用する場合、すこし正規表現が独特な記述法となることが多いです。Vimの正規表現に関しては、こちらをご確認下さい。


「^ * . 」などの、メタ文字を使って、文字のパターンを表せるんだね。